"SOLID가 왜 등장하게 되었을까?"라는 고민을 던져보면 사실 답은 크게 어렵지 않다. 많은 개발자들은 꾸준히 무언가를 해결하고자 했고, 자신들의 철학들을 꾸준히 코드에 녹여내려 했다는 점이라는 것이다. 즉, 객체 지향이라는 철학을 코드에 녹이려고 한 산출물이 SOLID이다.
따라서 SOLID를 충분히 이해하기 위해서는 객체 지향이란 무엇인가에 대한 고민을 꾸준히 할 필요가 있다는 것이다. 객체 지향과 SOLID는 항상 가까이 두어 정기적으로 읽어 내 습관처럼 만들어야 한다.
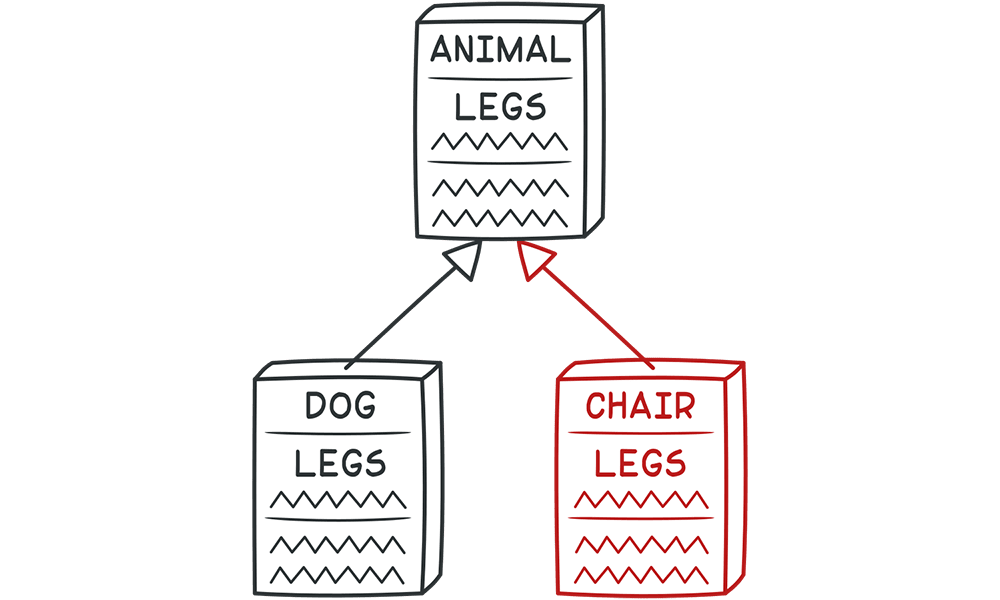
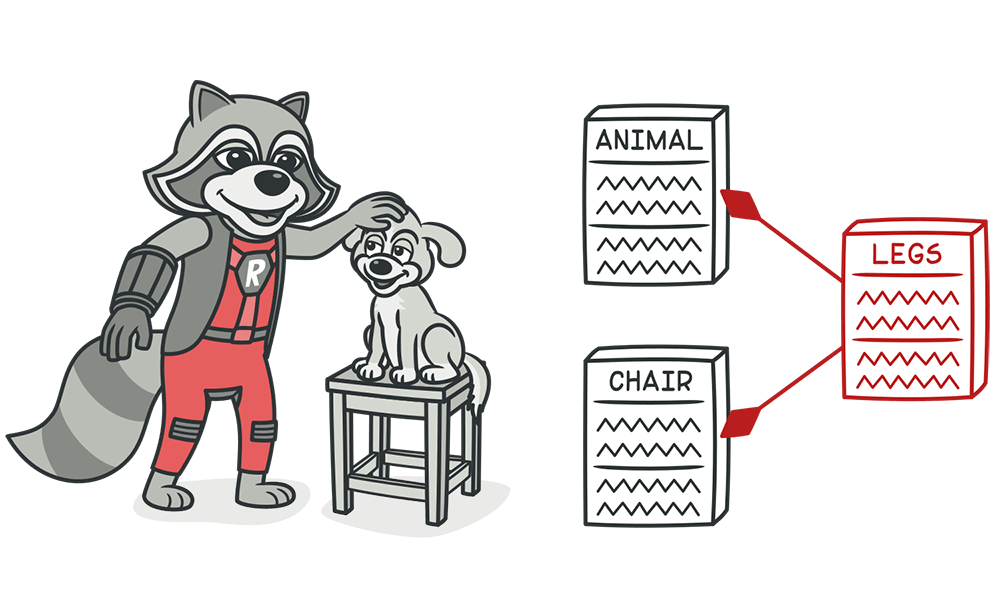
관심사의 분리 (SoC, Separation Of Concerns)
SOLID를 논한다면 항상 언급되는 것은 SoC가 아닐까 싶다. 관심사의 분리라는 말은 "관심이 같다면 모으고, 관심이 다르면 분리시켜 서로에게 영향을 끼치지 않도록 하는 것"이다. 이 관심사 분리에 해당하는 것은 속성, 메서드, 클래스, 모듈, 패키지 전부 포함된다. 이렇게 분리하는 이유가 무엇일까? 관심사가 다르다면 분명히 변화되는 시점이 다르기 때문이다.
이 전 포스팅에서도 언급했듯이, 분리가 많아지면 파일이 많아지는 것은 필연적이다. 하지만 객체 지향과 SOLID를 잘 녹여낸 코드를 만든다면 파일이 많아짐에도 불구하고 충분히 가치있을 것이다.
SoC를 잘 적용한다면 자연스럽게 인터페이스 분리 원칙(ISP), 단일 책임 원칙(SRP), 개방 폐쇄 원칙(OCP)에 도달하게 될 것이다. 스프링 또한 극한의 SoC를 추구한다.
SOLID의 각 원칙을 설명할 때는 한글화된 이름을 쓰기도 하지만, 대부분의 개발자들은 약어를 쓰더라. 필자도 면접에서 질문을 받았었던 기억이 있는데 SoC를 아는가 라고 물어봤다. 분명히 관심사의 분리라는 것은 기억하고 있었지만 SoC라는 약어에 대해서 익숙하지 않아서 "잘 모르겠습니다"라고 대답했다.
따라서 약어에 대해 익숙해지길 바란다.
SRP(단일 책임 원칙) : 하나의 클래스를 변경해야 하는 이유는 오직 하나 뿐이다.
OCP(개방 폐쇄 원칙) : 자신의 확장에는 열려있고, 주변의 변화에 대해서는 닫혀 있어야 한다.
LSP(리스코프 치환 원칙) : 서브 타입은 언제나 자신의 기반 타입으로 교체 가능해야 한다.
ISP(인터페이스 분리 원칙) : 클라언트는 자신이 사용하지 않는 메서드에 의존 관계를 맺으면 안된다.
DIP(의존 역전 법칙) : 자신보다 변하기 쉬운 것에 의존하지 마라.
객체 지향은 현실 세계를 반영한다고 했다. 즉 현실 세계에 대한 모델링이 객체 지향이라는 것이다. 더 생각해본다면, 객체 지향 세계는 모델링을 통해 추상화되었고, 현실 세계랑 같다. SOLID의 포커싱은 좀 더 모델링을 통한 추상화에 초점을 맞추고 있다.
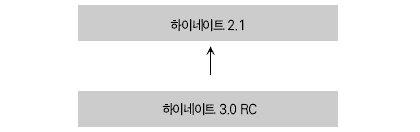
많은 기업들이 제공하는 API는 라이브러리 버전업을 할 때 하위 호환성을 고려해야 한다. 물론 여러 이유로 마이그레이션을 필요로 하는 버전업도 존재한다. 하나의 예로 하이버네이트 3.0 RC 버전이 출시 되었을 때 기존 버전과의 호환이 어려웠던 사례가 있었다. 하이버네이트가 결단력 있게 응집력 있는 라이브러리를 출시하고자 패키지 명도 변경했고, 인터페이스도 변경했다. 하지만 이러한 부분에 있어서 많은 개발자들이 불편을 겪었던 것은 사실이다.
라이브러리 버전 업에서 새로운 기능이 추가되더라도 기존 라이브러리를 사용하던 프로그램들은 수정 없이 상위 버전의 라이브러리를 사용할 수 있어야 한다. 인터페이스 제공은 애플리케이션 개발자와 라이브러리 개발자 간의 약속이기 때문이다.
필자가 사용하는 JDK는 오랜 기간 많은 사랑을 받아왔다. 그 이유는 기존 라이버리를 사용하던 프로그램들이 수정 없이 상위 버전의 라이브러리를 사용할 수 있었기 때문이다. 물론 몇몇 부분에서는 분명히 불편함을 겪었을 것이라 생각하지만 '약속'을 아주 잘 지킨 Best Practice라고 볼 수 있다.
LSP
개인적으로 SOLID를 공부하면서 가장 어려운 파트라고 생각한다. 부족한 설명이 있을 수 있음으로 지적할 사항이 있으면 꼭 댓글을 남겨주셨으면 한다.
라이브러리에서도 최신 버전은 이전 버전의 인터페이스를 준수하여 두 라이브러리의 교체가 문제가 되면 안되며, 상속 구조에서 기반 클래스를 파생할 수 있어야 한다. 이와 같은 하위 버전으로의 호환성 문제, 조금 더 쉽게 이야기하자면 서브 클래스의 기반 클래스로의 호환성 문제가 LSP 파트의 주제이다.
LSP 규약을 어기는 하나의 예를 보자.
public class Test {
public static void main(String[] args) {
String[] infoValues = new String[]{"info1??", "??info2??", "??info3??"};
List infoList = Arrays.asList(infoValues);
infoList = InfoHelper.addInfo(infoList);
}
}
class InfoHelper{
public static java.util.List addInfo(java.util.List currentInfo){
String info = "new info??";
currentInfo.add(info);
return currentInfo;
}
}
코드를 컴파일해서 실행시켜 보면 다음과 같은 에러가 발생한다.
여기서 발생한 예외는 Arrays.asList(infoValues)가 반환한 List 구현체가 List 인터페이스의 add() 메소드를 지원하지 않아서 발생한다. 다시 말해, List 인터페이스 중 add() 메소드가 제공되어야 한다는 구약이 지켜지지 않아서 생기는 에러란 이야기다. 이상하다. List 인터페이스는 분명히 add() 메소드를 제공하고 있지 않은가?
LSP는 구현이 선언을, Subclass 가 Superclass의 규약을 준수하여 사용자에게 하위 타입의 상세정보를 관심 밖으로 돌리는 기법을 다루고 있다. 따라서 다음과 같은 규칙이 보장되어야 한다.
서브 타입은 언제나 기반 타입으로 교체할 수 있어야 한다.
서브 타입은 언제든 기반 타입과 호환되어야 한다. 서브 타입은 기반 타입이 약속한 규약 (public 인터페이스, 메소드가 던지는 예외 포함) 을 지켜야 한다. 이 규칙은 라이브러리 버전 간의 관계에서도 동일하게 적용된다.
위의 예제에서 배열을 변환한 리스트를 다시 infoList = new ArrayList(inforList) 로 다시 생성하면 문제는 해소된다.
하지만 왜 배열을 List로 만들면 불변 리스트로 생성해야 하는가? 불변 리스트가 꼭 필요한 리스트인가? 뒤에서 살펴본 것처럼 불변 리스트가 LSP를 따르지 않는 것은 다른 특성 과의 트레이드 오프 결과이다. 하지만 여전히 Arrays.asList()의 결과가 불변 리스트인 것은 나도 이해가 안된다.
상속은 extends, implements 이든 궁극적으로 다형성을 통한 획득을 목표로 한다. LSP 원칙도 Subclass가 확장에 대한 인터페이스를 준수해야 함을 의미한다. 다형성과 확장성을 극대화하기 위해서 Subclass를 사용하는 것보다 Superclass를 사용하는 것이 좋다.
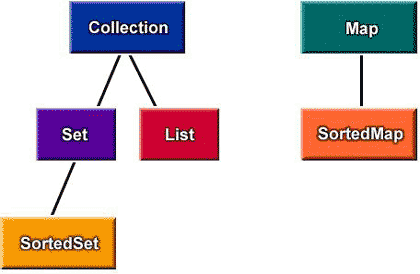
예를 들어 Collection 프레임워크를 이용할 때는 가능하면 Collection 인터페이스를 사용하고, Collection 인터페이스 사용이 불가하면 List, Set 인터페이스를 이용한다면 변경에 유연해진다.
따라서 ArrayList 등의 구체 클래스를 선언하는 것은 가능한 피해야 한다. 일반적으로 선언은 기반 클래스로 생성은 구체 클래스로 대입하는 방법을 사용한다. 생성 시점에서 구체 클래스를 노출시키기 꺼려지는 경우 생성 부분은 Abstract Factory 등의 생성 패턴을 사용하여 유연성을 높일 수 있다.
상속의 목적?
상속의 목적이 단지 재사용으로 생각이 든다면 다시 한번 곰곰이 생각해보자. 또한 상속을 통한 재사용은 concrete class와 subclass 사이에 IS-A 관계가 있을 경우로 제한해야 한다. 그 외는 합성을 이용한 재사용을 해야 한다. 예를 들어 Stack 클래스는 Vector 클래스를 extends 하여 만들었다. 하지만 Stack is Vector는 성립하지 않기때문에 상속 대신 합성을 사용해야 했다. 왜냐고? Stack은 인덱스를 통한 접근을 제공하는 get() 메소드를 제공하면 안 되기 때문이다. 즉 Stack과 Vector 관계는 개념적으로 상속 관계가 성립하지 않는다. 물론 Java의 Stack은 인덱스 접근이 가능하다. 하지만 이는 우리가 학부 과정에서 배운 자료구조를 생각해 봤을 때 올바른 사용이 아님을 기억해야 한다.
상속과 다형성
상속과 다형성은 분리할 수 없는 샴쌍둥이 같은 존재다. 다형성으로 인한 확장 효과를 얻기 위해서는 Subclass가 concrete 클래스와 클라이언트 간의 규약 (인터페이스) 를 지켜야 한다. 이 구조는 결론적으로 다형성을 통한 확장의 원리인 OCP를 제공하게 된다. 따라서 LSP는 OCP를 구성하는 구조가 된다. 따라서 원칙들에 대해서 따로 다루지만 사실 서로를 이용하고 포함하는 관계에 있다.
LSP는 규약을 준수하는 상속 구조를 제공한다. LSP를 바탕으로 OCP는 확장하는 부분에 다형성을 제공해 변화에 열러 있는 프로그램을 만들 수 있도록 해준다.
컬렉션 프레임워크를 통해 OCP, LSP 적용 사례
컬렉션 프레임워크는 크게 Collection, Map이라는 인터페이스를 갖고 있다. 자바 1.2에서 도입된 컬렉션 프레임워크는 객체 지향의, 객체 지향에 의한, 객체 지향을 위한 프레임워크 라고 할 수 있다. 또한 OCP와 LSP의 바람직한 예이다.
void f(){
LinkedList list = new LinkedList();
modify(list);
}
void modify(LinkedList list) {
list.add();
doSomething(list);
}
위와 같은 코드가 있다. 이 코드에서 LinkedList만 사용한다면 전혀 문제가 될 부분은 하나도 없다. 하지만 속도 상의 문제로 HashSet을 사용해야 한다면? LinkedList와 HashSet은 Collection 인터페이스를 상속하고 있기에 다음과 같이 작성하는 것이 가장 바람직하다.
위와 같이 작성한다면 컬렉션 구현 클래스는 어떤 것이든 사용할 수 있게 된다. 여기서 LSP와 OCP 모두를 찾아볼 수 있다. 만약 컬렉션 프레임워크가 LSP를 준수하지 않았다면 Collection 인터페이스를 통해 수행하는 범용 작업이 제대로 수행될 수 없다. 하지만 Arrays.toList()의 경우와 불변 컬렉션을 제외하고는 모든 Collection 연산에서는 앞의 modify 메소드가 올바르게 동작할 것이다.
또한 modify() 메소드는 변화에 닫혀 있으면서, 컬렉션의 변경과 확장에 대해서는 OCP를 충족한다. 물론 Collection이 지원하지 않는 연산을 사용한다면 한 단계 계층 구조를 내려가야 한다. 그렇다고 하더라도 ArrayList, LinkedList, Vector 대신에 List를 쓰는 현명한 판단을 하길 바란다.
트레이드 오프
모든 선택에는 트레이드 오프가 있다. 항상 LSP를 지킬 수 있다면 더 없이 좋겠지만 안타깝지만 현실이 그러하다. Collection 프레임워크에서 LSP를 어겼지만 올바른 선택이였다고 하는 예를 보겠다.
Collection list = new LinkedList();
list = new Collections.unmodifiableCollection(list);
Collections의 unmodifiableCollection 메소드를 이용하면 불변 컬렉션 객체를 만들 수 있다. 불변 컬렉션 객체에 대해 add() 혹은 remove() 등의 메소드를 호출하게 되면 위에서 보았던 UnSupportOperationException을 던지게 된다. LSP 위반이다. 당연히 제공해야 됨에도 불구하고 이렇다. 왜 그런가? Wrapper를 이용하지 않는 다면 이 계층 구조는 2배로 커진다. Collection 인터페이스가 ModifiableCollection과 UnmodifiableCollection으로 나누어져야 하고, 이를 구현하는 모든 서브 클래스들 또한 숫자가 두 배가 된다.
Collection 프레임워크를 선택한 Joshua Bloch는 계층 구조의 폭주와 LSP 위반 사이에서 LSP 위반을 택했다. 생각만 해도 폭주되는 계층 구조는 끔찍하지 않은가. 때로는 이러한 트레이드 오프도 결정할 수 있는 개발자의 능력이 필요하다는 것이다.
리팩토링
LSP를 지키지 않는 다면 Refused Bequest라는 악취가 난다. 코드에 악취가 난다는 말은 조금이라도 클린 코드에 관심을 가졌다면 알 것이다.
① 부모를 상속한 자식 클래스에서 메쏘드를 지원하는 대신 예외를 던진다(예를 들어 콜렉션 프레임워크에서 UnsupportedOperationException)
② 자식 클래스가 예외를 던지지는 않지만 아무런 일도 하지 않는다.
③ 클라이언트가 부모보다는 자식을 직접 접근하는 경우가 많다.
이에 대한 해결책은 다음과 같다.
① 혼동될 여지가 없고 여러 트레이드 오프를 고려해 선택한 것이라면 그대로 놔둔다. 단 트레이드 오프와 프로그램의 범용성의 한계에 대해서 스스로 인지하고 있어야 한다.
② 다형성을 위한 상속 관계가 필요없다면 Replace Inheritance with Delegation을 한다. 상속은 깨지기 쉬운 기반 클래스 등을 지니고 있으므로 IS-A 관계가 성립되지 않는다. LSP를 지키기 어렵다면 상속 대신 합성(composition)을 사용하는 것이 좋다.
③ 상속 구조가 필요하다면 Extract Subcless, Push Down Field, Push Down Method 등의 리팩토링 기법을 이용하여 LSP를 준수하는 상속 계층 구조를 구성한다.
객체 지향의 정점 "다형성"
사실 이 포스팅을 접하기 전까지 객체 지향의 꽃은 상속을 통한 재사용이라 생각했다. 하지만 SOLID를 공부하는 과정에서 상속의 목적이 다형성을 극대화하기 위한 부분이라는 생각이 들었다. 객체 지향 프로그래밍은 캡슐화, 상속, 그리고 다형성을 기초로 한다. 캡슐화를 지키기 위해 내부의 데이터와 구현은 외부로 노출시키지 않고 public 인터페이스만 개방해야 한다. 이 때 public 인터페이스는 객체와 외부 클라이언트 사이의 약속 계약이며, 이는 상속과 다형성을 위한 걸음마가 된다. 이 전 포스팅에서 SRP는 각 객체가 어떤 역할을 캡슐화 할 것인지에 대한 가이드를 제공한다.
잘 정의된 상속 구조는 concrete class와 Subclass 간의 IS-A 관계가 성립하며 concrete class는 사용자로부터 구체 구현 클래스를 캡슐화 한다. Collection 인터페이스는 List와 Set을 캡슐화해주고, List는 ArrayList와 LinkedList, Vector를 캡슐화해주는 형태다. 스프링 MVC 패턴에서 서비스 레이어에서 Service 인터페이스와 ServiceImpl 구현체를 사용하는 것은 캡슐화를 위함이였던 것이다. 또한 객체를 생성하는 부분에서만 구체 클래스가 사용되는 데 이 또한 Abstract Factory 등의 생성 패턴을 사용해 적절히 추상화시킬 수 있다(JDBC를 생각해 보자). 그리고 LSP가 상속이 다형성을 위해 사용될 수 있도록 해준다. LSP를 지키지 않으면 Arrays.asList()와 같이 상속 구조에 포함되어 있다 하더라도 다형성으로 인한 이점을 제대로 살리지 못하게 된다.
마지막으로 다형성이야 말로 확장 가능하고 유지보수하기 쉬운 소프트웨어를 만들 수 있게 해주는 객체지향의 꽃이다. 하지만 다형성을 얻으려면 우선은 각 객체들이 적절히 책임 분배되어 있고, 캡슐화되어 있어야 하며, 다형성을 얻을 수 있는 부분은 LSP를 준수하는 상속 구조를 보장해야 한다. 그러므로 캡슐화와 SRP, 상속과 LSP가 제대로 되지 않은 객체 구조에서는 다형성과 OCP를 제공할 수 없다. 다음은 적절히 책임이 분배되지 않은 객체 구조를 SRP, LCP, OCP를 준수하는 객체 구조로 진화시켜 나가는 과정을 잘 보여준다.
개발자들은 가능한 단순한 구조, 프로그램의 완전성 그리고 수정의 용이함이란 서로 상충하는 특성을 갖는다. 객체지향 시스템은 본질적으로 절차지향 시스템에 비해 구조가 복잡하지만, 확장하고 유지보수하기 쉬우며 직관적이다. 디자인 패턴 역시 프로그램의 복잡도를 증가시키지만 역시 확장과 유지보수를 용이하게 해준다. 우리는 본질적으로 복잡한 세상을 다루고 있다. 그렇기 때문에 복잡성 자체를 피할 수 없다. 대신 복잡성을 관리하는 방법에 대해 찾으려고 노력해야 한다.
이에 대한 명쾌한 하나의 답은 없다. 객체지향 시스템을 사용하여 복잡성을 관리하려 한다면 객체지향의 특질, 그리고 이들의 장점과 단점을 파악하고, 문제 상황에서 적절히 트레이드 오프하면서 최선의 선택을 찾을 뿐이다. 즉, 그때 그때 다르다. 다행히 여러 객체지향의 특질, 원리, 패턴은 복잡한 상황 속에서 (복잡성을 고려한다면) 최대한 단순한 구조와 용이한 수정과 확장을 가능하게 해준다. 하지만 상황에 따라 이들을 어길 수도 있다. 하지만 왜 어길 수밖에 없는지, 그리고 이로 인한 장점과 단점이 무엇인지는 분명히 알고 선택해야 한다. 트레이드 오프와 장점과 단점을 생각하지 않은 선택은 라이트 없는 야간 비행을 시도하는 것이다
DIP (Dependency Inversion Principle) 은 의존 관계 역전 원칙이라 명명되었다. 개인적인 생각이지만, DIP 는 개발의 패러다임이 바꿨다 할 수도 있을 것 같다. 그만큼 중요한 내용이고, 이해하려고 노력하였으나 개인적으로 DIP를 이해하는 것이 쉽지 않았다고 생각한다. 물론 지금도 완벽한 이해를 하고 있는것은 아니라 생각한다. 시작 해보자!
의존 관계 역전의 법칙
포스팅을 공부하면서 개발자로서 꼭 읽어봐야 할 서적이 한 개 더 추가됐다. 읽을 책이 늘어난다는 것은 나름대로 기분 좋고 행복한 일이다. GoF (Gang of Fours). Design Patterns 책에서 "템플릿 메소드" 패턴을 소개하면서 헐리우드 원칙을 이야기한다
헐리우드 원칙이란 캐스팅 프로세스에서 배우가 직접 영화기획사에 전화하는 방식으로 진행되었던 부분을 배우는 자신이 자신있는 역할이나 어떤 영화 배역을 맡고 싶다고 등록하면, 영화기획사가 선별하여 전화하는 프로세스로 변경한 것
헐리우드 원칙을 적용하여 얻고자 했던 효과는 무엇일까? 살펴보면 헐리우드 원칙 이전의 캐스팅 프로세스는 영화 기획사는 누가 봐도 수동적이며, 배우는 능동적이다. 하지만 이 과정에서는 영화 기획사는 많은 배우들의 전화에 시달려야 하며, 배우는 직접 찾아서 전화해야 되는 노동이 숨겨져 있다.
헐리우드 원칙을 적용함으로써? 그 고된 노동을 큰 폭으로 줄일 수 있다는 것이다. 배우는 단순히 자신의 정보를 등록하면 되며 기획사는 필요한 배우에게 연락하면 된다. 확실히 프로세스가 간편해 지지 않는가? 따라서 기존의 능동적인 배우, 수동적인 기획사는 헐리우드 원칙을 적용함으로써 "수동적인" 배우, "능동적인" 기획사로 역전 된다.
그래서 의존 관계 역전의 법칙이라 하며, DIP에도 이 헐리우드 원칙의 구조와 목적을 그대로 도입한다고 생각하면 된다.
통제권의 역전
이전의 구조 지향 프로그래밍과 객체 지향 프로그래밍의 프레임워크 사용 방법을 비교해보겠다. 구조 지향적 프로그램은 main() 함수에서 시작해서 여러 함수들을 호출하는 것으로 프로그래밍 매우 절차적이다.
반면 프레임워크를 사용하는 방식은 프레임워크에 객체를 등록하므로 실행의 통제권을 프레임워크에게 위임한다. 단편적으로 HTTP 서버에 서블릿을 등록하고 HTTP 서버에게 서블릿 실행을 요청하는 URL이 접수되면 HTTP 서버는 등록된 서블릿을 실행한다. 직관적으로 이해가 잘 되지 않을 것이다. 나도 그랬다. 그러니 아까 이야기했던 할리우드 원칙을 적용해 비교해보겠다.
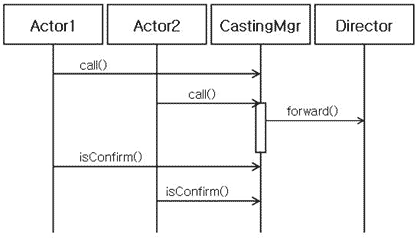
[그림 1]
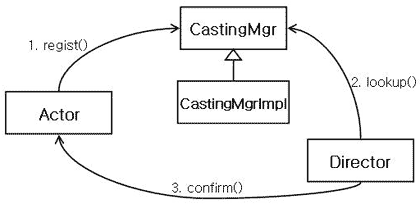
[그림 2]
[그림 1]을 보자. Actor라는 존재가 직접 CastingMgr에게 전화를 하고 CastingMgr은 Director에 전달한 다음 Actor가 다시 확인을 하는 Process며 이 과정에서 통제권이 Actor에게 있다. 통제의 흐름은 호출자(Caller, =Actor)에서 서비스 함수(Callee, =CastingMgr)에게 이전되며, 서비스 함수 루틴이 종료되면 다시 호출자에게로 통제가 반환된다. 따라서 CastingMgr은 Actor의 요청에 대해 수동적으로 서비스한다.
[그림 2]를 보자. Actor는 CastingMgr에게 자신을 regist 한다. 그리고 이전에는 단순히 호출 받기만 했던 Director는 Actor에게 직접 confirm()을 실행한다. 두 관계가 역전이 된 것이다. 이것을 '통제권의 역전(Inversion of Control)'이라 한다. 추후 스프링 프레임워크를 공부할 일이 있다면, 근간이 되는 개념이라 볼 수 있으니 기억해두면 좋을 것이다.
DIP가 포스팅 주제인데, "왜 IoC를 이렇게 길게 다루지" 에 대한 의문이 생겼을 수도 있지만, IoC는 DIP의 중요한 골격이 된다. 이제 좀 더 집중해야 될 시간이다.
서비스 요청자(Actor)는 서비스 제공자(프레임워크)에게 자신을 등록하고 서비스 제공자는 서비스를 마친 후 서비스 요청자에게 미리 정의해 둔 인터페이스를 통해 결과를 알려준다.
이 문장을 쉽게 풀어보겠다.
Actor는 서비스 제공자인 CastingMgr에 자신을 등록하고 CastingMgr은 서비스를 마친 후 Actor에게 미리 정의해둔 인터페이스 confirm()을 통해 결과를 알려준다.
중요한 포인트다. 미리 정의해둔 인터페이스는 훅(Hook) 메소드라 부르며 훅 메소드는 '역전'을 위한 매개 포인트가 된다. 추후 포스팅에서도 계속 등장하기 때문에 꼭 기억해두길 바란다.
훅 메소드? 확장성을 확보하는 기능
'미리 정의해둔 인터페이스'로 다양한 루틴을 정의할 수 있다. 가령 서블릿 개발을 해 본 사람이라면 doGet() 이나 doPost() 와 같은 인터페이스가 있다는 것을 알 것이다. 이러한 인터페이스는 개발자로부터 무한한 확장을 제공한다. 단지 서블릿 컨테이너는 서블릿 호출이 왔을 때 해당하는 서블릿의 doGet()이나 doPost()을 실행하면 된다.
자 그럼 doGet(), doPost() 메소드의 역할을 다시 한번 짚어보자.
doGet(), doPost() 메소드는 개발자에게 있어 확장성을 제공한다.
doGet(), doPost() 메소드는 서블릿 컨테이너에게 있어 훅 메소드의 역할을 한다.
자 그럼 IoC를 골격으로 하는 DIP로 얻을 수 있는 것은 무엇일까?
DIP
허허.. DIP를 이야기하는 줄 알고 들어봤더니 서두가 겁나 길다. 할 수 있을 것이다. 나도 짧고 명확하게 이해가 잘 되는 글을 좋아한다. 하지만 이 DIP는 길어질 수 밖에 없다.
[그림 3]
DIP에서도 훅 메소드를 통해 확장성을 제공한다. 이미 정의된 인터페이스를 통해서 확장을 보장하고, 이 인터페이스는 사용자로부터 사용자가 정의한 컴포넌트를 은닉시켜 사용자 정의 컴포넌트에 대한 의존성을 제거하기 위함이다. 즉 확장성을 보장하기 위해 추상화가 이용된다.
어렵다. 계속 가보겠다.
OCP와 DIP가 다른 점은 DIP는 IoC를 한다는 것이다. 더 어렵다. 이해가 안된다.
천천히 다시 이해해보자.
[그림 1]에서 [그림 3]과 같이 confirm()이란 인터페이스를 여러 Actor의 자식들이 확장할 수 있다. 만약 confirm()을 확장한 Actor들이 프레임워크에 등록 됐을 때 confirm()은 훅 메소드가 된다. 따라서 DIP는 확장되는 훅 메소드를 정의하기 위해 OCP를 이용하고 있다. 설계의 원칙은 이렇게 서로 관계성을 가지고 있으며 서로가 서로를 포함하기도 하고 이용하기도 한다.
DIP 케이스
사례는 꼼꼼히 읽어봤으면 좋겠다는 생각으로 스크랩을 한다.
사례 1 : 통신 프로그래밍 모델
일반적으로 소켓 프로그램은 클라이언트가 서버에게 요청을 send()하고 서버로부터 결과를 recv()하므로 서버의 서비스를 이용하게 된다. 멀티쓰레드 프로그래밍에서 이 send() & recv()를 하게 되면 recv()하는 동안 쓰레드는 서버의 응답이 오기까지 대기하게 된다. recv() 함수는 블럭되기 때문이다. 따라서 이 때 recv()하는 모든 쓰레드들은 블럭되기 때문에 쓰레드 자원이 아까워진다. 왜냐하면 서버로부터의 응답을 받기 위해 대기하는 동안 recv()를 호출한 쓰레드는 다른 작업을 할 수 없기 때문이다.
이 방식의 대안으로 제시되는 모델이 폴링(polling) 모델이다. 클라이언트 쓰레드는 서버에게 메시지를 보내고 recv()를 전담하는 쓰레드에게 recv()를 맡긴다. 그리고 이 쓰레드들은 다른 작업을 실행하면서 계속 일을 한다. 서버로부터 응답을 확인하고 싶은 시점에서 접수된 서버의 메시지를 가져온다. 따라서 클라이언트 쓰레드는 다른 일을 할 수 있는 기회비용을 얻을 수 있다.
하지만 폴링 모델에서 어느 순간 클라이언트 쓰레드는 서버의 응답을 확인해야 한다. 단지 자신이 원하는 시점에 서버의 응답을 확인하는 장점과 응답을 기다리는 시간에 다른 작업을 할 수 있는 기회를 확보할 뿐이다. 이 모델까지는 확실히 모든 통제가 클라이언트 쓰레드의 스케쥴 안에 있다. 그리고 동기적으로 (자신이 원하는 시점에) 서버의 응답을 확인할 수 있다. 하지만 만약 서버의 응답이 예상보다 지연될 경우 클라이언트 쓰레드는 서버의 응답이 올 때까지 여러 번 응답 큐를 확인하는 비용이 따른다. 또한 서버의 응답을 확인하는 시점이 동기적이지 않아도 될 경우 더더욱 이 확인 작업은 지난해지게 된다. 즉, 서버의 응답에 대한 처리가 비동기적이어도 될 때, 그리고 클라이언트 쓰레드가 서버의 응답 확인하는 시도가 여러 번 발생할 때 폴링 모델도 오버헤드를 얻게 된다.
이 때 DIP를 적용하기 적당한 시점이 되는데 클라이언트 쓰레드는 메시지를 send()한 후에 recv()하는 대신 서버의 응답을 처리하는 훅 메쏘드를 Reply DeMuxer에 등록한다. - 구조적 프로그램에서는 함수 포인터를 등록하지만 객체지향 세계에서의 트렌드는 커멘드 오브젝트를 등록한다(GoF의 커멘드 패턴 참조). Reply DeMuxer의 recv()를 담당하는 쓰레드는 서버로부터 응답을 접수하면 대응하는 훅 메쏘드를 찾아 훅 메쏘드를 실행한다. 즉 recv() 쓰레드는 서버의 응답 접수(여기까진 폴링 모델)와 훅 메쏘드 실행을 담당한다.
이 모델은 비동기 소켓 모델로서 DIP의 원칙을 그대로 따르고 있다. - 클라이언트 쓰레드들은 헐리우드 원칙에서의 배우로 receive 쓰레드는 영화기획사 담당자로 등치해 보라. 비동기 모델에서 얻을 수 있는 장점은 첫째, 클라이언트 쓰레드의 잦은 응답 확인을 제거할 수 있다. 둘째, 클라이언트 쓰레드는 응답을 확인하는 작업에서 자유로워지므로 다른 작업을 할 수 있는 기회비용을 확보할 수 있다. 물론 이 과정은 비동기적으로 이루어져도 괜찮은 상황에 한한다.
무엇보다 중요한 것은 이런 구조의 바탕에는 통제권이 클라이언트 쓰레드에서 Reply DeMuxer로 역전되는 IOC가 전제된다. DIP를 적용할 때 기대할 수 있는 장점은 상술한 두 가지 장점을 그대로 확보하는데 있다. 퍼포먼스를 높이고 요청에 대한 응답으로부터 관심을 제거하여 클라이언트의 역할을 단순화하는데 있다.
사례 2 : 이벤트 드리븐, 콜백 그리고 JMS 모델
자바 API는 소프트웨어 설계의 좋은 모델이 된다. 반면에 개발자로서 하고 싶은 마법들을 API 수준에서 제공해주니 마법을 부릴 기회가 줄어들어 약간 억울하기까지 하다. 자바 스윙에서 이벤트 모델에도 마법이 녹아 있다. 자바 스윙 컴포넌트는 이벤트를 처리할 java.awt.event.ActionListener를 등록(addActionListener())한다. 이 스윙 컴포넌트에 이벤트가 발생하면 등록된 ActionListener의 훅 메쏘드인 actionPerformed()를 후킹한다. 스윙 컴포넌트에는 복수 개의 ActionListener를 등록할 수 있는데 이유는 복수 개의 이벤트가 발생할 수 있기 때문이다. 이와 유사한 구조로 더 일반화된 Observer & Observable 인터페이스도 있다.
더 나아가서 분산 시스템에서도 똑같은 구조가 적용된다. 서버와 클라이언트간의 통신에 있어서 클라이언트는 서버에 자신의 원격 객체 레퍼런스를 등록한다. 서버는 자신의 작업을 진행하면서 원격 객체 레퍼런스를 통해 그때그때 필요한 정보를 클라이언트에게 제공한다. 이 구조를 위해서 클라이언트의 콜백(callback) 메쏘드가 미리 정의되어 있어야 한다. 콜백 메쏘드는 서버가 비동기적으로 클라이언트에게 정보를 전달하는 훅 메쏘드가 된다. 따라서 콜백의 구조는 원격지에서 훅킹이 제공되는 형태를 갖는다.
이와 같은 구조는 비동기적인 분산 훅킹(콜백)구조를 형성할 때 사용된다. 가령 서버에게 장시간의 작업들을 할당하고 클라이언트가 각 작업의 결과에 대한 중간보고를 비동기적으로 받고 싶을 때 유용하다. 클라이언트의 호출이 비동기적이기 때문에 서버의 작업을 할당한 다음 클라이언트는 다시 자신의 작업이 진행된다. 따라서 앞서 예시한 소켓의 비동기 모델에서 recv() 쓰레드가 서버의 역할로 전이된 형태를 갖는다.
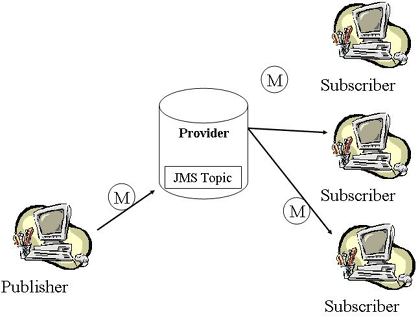
JMS의 토픽 모델은 좀 더 다양한 구조를 갖는다. - 이 모델은 전통적인 MOM 아키텍처에서 Publish/Subscribe 메시징 모델로 알려져 있다. 이 모델은 멀티캐스팅 같은 그룹 메시징을 제공할 때 유용한데, 가령 주식정보 시스템을 예로 들었을 때 주식정보 제공자는 가입한 모든 클라이언트에게 현재 증시정보를 멀티캐스팅한다. 이 때 주식정보 제공자는 Publisher가 되고 클라이언트 프로그램은 Subscriber가 된다.
참고로 이 모델의 장점은 클라이언트/서버에서 메시지 기반으로 패러다임이 바뀐다는 것이다. 기존의 클라이언트/서버 모델의 경우 서버는 클라이언트들을 상대한다. 따라서 클라이언트의 위치 정보와 인터페이스 등을 알아야 한다. Publish/Subscribe 모델에서는 이 클라이언트와 서버 간의 상호의존도가 제거된다.
이제부터 서버는 각종 클라이언트들에게 메시지를 보내는 것이 아니라 그냥 ‘주식정보’라는 메시지를 보내면 될 뿐이다. 즉, 어떤 클라이언트들이 얼마나 접속되어있는지, 각 클라이언트들의 위치와 인터페이스는 어떤지 등의 여부와 같은 클라이언트 정보는 관심 대상에서 제외되고(주식정보라는) 메시지에 관심을 집중하게 된다. 이 패러다임은 클라이언트가 몇 개 접속되어 있는지 혹은 아예 없든지, 클라이언트의 상태나 위치가 어떤지에 관심 없이 그룹 메시징 제공자에게 메시지를 보내기만 하면 될 뿐이다.
이 모델에서 Subscriber들은 Topic 제공자에게 자신을 등록한다. Publisher가 Topic 제공자에게 메시지를 전송하면 JMS Topic 제공자는 등록된 Subscriber들에게 메시지를 멀티캐스팅한다. 이 때 메시지 멀티캐스팅을 하기 위해 등록된 각 Subscriber들의 onMessage()를 호출하게 된다. 그럼 상술한 훅 메쏘드들, 즉 ActionListener.actionPerformed(), MessageListener.onMessage(), 그리고 콜백 메쏘드는 어떤 의미를 가질까? 훅 메쏘드는 IOC이면서 확장 인터페이스를 제공한다. 사용자 정의 컴포넌트들이 자신의 목적에 맞게 이 메쏘드를 확장하여 사용할 수 있게 하기 위함이다.
정리
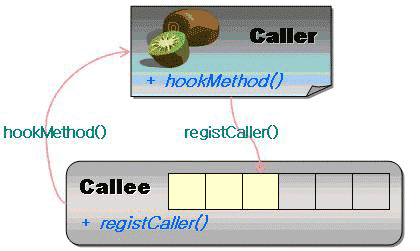
DIP의 키워드는 ‘IOC’, ‘훅 메쏘드’, ‘확장성’이다. 이 세 가지 요소가 조합되어 복잡한 컴포넌트들의 관계를 단순화하고 컴포넌트 간의 커뮤니케이션을 효율적이게 한다. 이 목적을 위해 Callee 컴포넌트(예를 들어 프레임워크)는 Caller 컴포넌트들이 등록할 수 있는 인터페이스를 제공해야 한다. 따라서 자연스럽게 Callee는 Caller들의 컨테이너 역할이 된다(JMS의 Topic 제공자, 스윙 컴포넌트, 배우 섭외 담당자들은 등록자들을 관리한다). Callee 컴포넌트는 Caller 컴포넌트가 확장(구현)할, 그리고 IOC를 위한 훅 메쏘드 인터페이스를 정의해야 한다. Caller 컴포넌트는 정의된 훅 메쏘드를 구현한다.
이로써 DIP를 위한 준비가 완료됐다. 이 상태에서 다음과 같은 시나리오가 전개된다. Caller는 Callee에게 자신을 등록한다. Callee는 Caller에게 정보를 제공할 적당한 시점에 Caller의 훅 메쏘드를 호출한다. 바로 이 시점은 Caller와 Callee의 호출관계가 역전되는 IOC 시점이 된다. DIP를 이용해서 얻을 수 있는 장점은 무엇일까? 이 질문은 DIP를 사용할 수 있는 상황과도 밀접하게 연관되어 있다.
DIP는 다음과 같은 상황에서 사용된다. 비동기적으로 커뮤니케이션이 이루어져도 될 (혹은, 이뤄져야 할) 경우 컴포넌트 간의 커뮤니케이션이 복잡할 경우 컴포넌트 간의 커뮤니케이션이 비효율적일 경우(빈번하게 확인해야 하는)에 사용된다. DIP는 복잡하고 지난한 컴포넌트간의 커뮤니케이션 관계를 단순화하기 위한 원칙이다. 실세계에서도 헐리우드 원칙에서와 같이 귀찮도록 자주 질문과 요청하는 동료에게도 써먹어 볼만한 원칙이다.
직역하면 단일 책임 원칙이다. 사실 직관적인 단어라 어려운 부분이 없다고 생각했다. 하지만 예시를 확인해 봤을때 이게 뭔 말인가? 했다. 그래서 가지고 있던 책 중에 클린 코드를 확인 해보았다.
단일 책임 원칙은 클래스나 모듈을 변경할 이유가 단 하나뿐이어야 한다.
아! 나는 기존에 정의된 하나의 클래스에 하나의 책임만을 가져야 된다는 것보다 이게 더 직관적으로 와닿았다.
Dashboard라는 클래스를 예시로 설명해보겠다.
public class Dashboard extends JFrame implements MetaData
{
public Componet getLastFocusComp()
public void setLastFocus(Component lastFocus)
public int getMajorVersionNum()
public int getMinorVersionNum()
public int getBuildNum()
}
여기서 Dashboard의 역할은 두 개로 가정한다. 소프트웨어 버전 정보를 추적, Dashboard는 스윙 컴포넌트를 관리. 하지만 소프트웨어는 출시될때마다 버전 정보가 변경되며, 스윙 코드를 변경할 때마다 버전 번호가 달라진다. 자, 그럼 여기서 코드를 변경해야 하는 이유가 두 가지나 된다는 것이다.
따라서 이 코드에서 냄새를 제거해보자. 변경되는 이유를 찾았으니, 버전 정보를 다루는 메소드를 추출해서 새로운 클래스를 생성해보자. 여기서 버전 정보를 관리하는 메소드는 아래와 같다. 이를 Version 클래스로 만들어보자.
public class Version {
public int getMajorVersionNum()
public int getMinorVersionNum()
public int getBuildNum()
}
이렇게 만들어진 Version 클래스는 다른 애플리케이션에서도 충분히 쉽게 사용될 것이다.
많은 주니어 개발자들은 깨끗하고 체계적인 소프트웨어보다 돌아가는 소프트웨어에 초점을 맞추는데, 사실 이건 비교하면 잘 정리된 여러 개의 수납장에 물건을 정리해서 사용할 것이냐? 큰 서랍장 하나에 모든 물건을 던져놓고 쓸 것이냐? 이다. 느껴지지 않는가? 냄새나는 코드의 제거는 중요하다.
소프트웨어 구성 요소 ( 컴포넌트, 클래스, 모듈, 함수 ) 는 확장에 대해서는 개방되어야 하며, 변경에 대해서는 폐쇄되어야 한다. 이는 다시 말해 변경을 위한 비용은 가능한 줄이고 확장을 위한 비용은 가능한 극대화해야 한다는 의미다.
이를 달성하기 위해서는 변경되는 부분, 변경되지 않는 부분을 엄격하게 구분해야 한다. 구분을 통해서 변하는 것은 가능한 변하게 쉽게하고, 변하지 않는 것은 변하는 것에 영향을 받지 않도록 하는 것이다. 그리고 인터페이스를 변하는 것과 변하지 않는 것의 중간 지점에서 서로를 보호하는 중재자 역할을 해야된다.
따라서, 이를 통해서 얻을 수 있는 것은 객체 간의 관계를 단순화해 복잡도를 줄이고, 확장이나 변경에 의해 발생하는 충격을 줄일수 있다.
혹시 복잡한가?
그럼 좀 더 쉽게 로버트 C.마틴의 말을 인용해보겠다. "소프트웨어 엔티티는 확장에 대해서는 열려 있어야하고 , 변경에 대해서는 닫혀있어야 된다." 라는 말을 쉽게 풀어보면 "나는 확장될 수 있어야하며, 다른 사람이 변하더라도 나에게 영향을 끼치면 안된다". 좀 더 이해가 됐으면 좋겠다.
자, 위 포스팅에서는 중재자의 역할, OCP의 인터페이스 기능으로 하는 예로 24핀 표준 규격의 충전기를 든다. 공통된 규격의 충전기는 사용자가 충전기를 사용함에 있어서 신뢰할 수 있고, 충전기 제공자는 목적에 맞게 확장, 특화하여 차별화나 상품성을 높일 수 있다. 물론 지금은 USB-C type이 표준이라 볼 수 있겠다.
하나의 예를 더 들어보자.
스프링 입문을 위한 자바 객체 지향의 원리와 이해에 들어있는 예제를 보겠다..
위 [그림 1]을 보게 되면 운전자는 기존에 마티즈를 타다가 새로운 자동차 소나타를 구매했다. 차량 종류를 변경하자 기본에 마티즈에서 수동으로 하던 일을 자동으로 변경되었다. 단순히 스틱 차량에서 오토 차량으로 변경되었다고 해서 기존의 운전자의 역할이 변화되어야 되는가? 현실 세계에서 봤을때는 어느 정도 Yes 라는 대답은 하겠지만, 객체 지향에서는 아니다. OCP에 위반되기 때문이다. 그럼 어떻게 해야하는가?
다소 위 예제가 억지스럽다고 느낄 수 있지만, 그려려니 해주셨으면 한다.
[그림 2]와 같이 기존의 공통된 특성을 추출하여 클래스나, 인터페이스를 생성하면 운전자 클래스는 다양한 자동차가 생긴다 하더라도 운전자 클래스에는 영향을 끼치게 않게 된다. 또한 자동차 입장에서는 확장에는 개방되어 있다.
개방 폐쇄 원칙에 대해서 이 글을 보며 조금이라도 이해했다면? 대표적인 개방 폐쇄 원칙을 지킨 가장 큰 예제는 JDBC이다.
JDBC를 사용하는 클라이언트는 데이터베이스가 오라클, MySQL, MariaDB 어떤 데이터베이스를 사용하더라도 Connection을 설정하는 부분을 제외하고는 모두 동일하게 사용 가능하다.
자신의 코드는 수정할 필요가 없이 변화에 대해서는 닫혀있으며, 다양한 데이터베이스 연결에 대해서는 확장에 열려있다고
볼 수 있다. 이러한 개방 폐쇄 원칙을 잘 지킴으로써 완충 역할을 하고 있는 것이다.
OCP 주의점
여기서 3가지 주의점에 대해서 언급한다. 아직 주니어 개발자라 격하게 공감하지 못하지만 명언처럼 마음에 담아두게 되었다.
공통 모듈 설계
공통된 루틴이나 변수를 리팩토링하여 분리를 하게 되었을 때, 공통 모듈이 작을 경우 공통 모듈 재사용을 얻기 위해 너무 잦은 모듈을 접근해야 하고 모듈 구성도를 지저분하게 할 경향이 높다. 설계자의 좋은 자질 중 하나는 OCP에서 확장되는 것과 변경되지 않는 모듈을 분리하는 과정에서 크기 조절을 잘 할 수 있는 결단력이라는 것이다.
확장을 보장하는 Open 모듈에서 인터페이스의 변경인가, 어댑터 사용인가
확장을 보장하는 open 모듈 영역에서 예측하지 못한 확장 타입을 만났을 때 인터페이스 변경하려는 안과 어댑터를 사용하려는 안 사이에서 갈등하게 된다. 위의 두 예에서처럼 변경의 충격이 적은 후자를 택하는 경우가 대부분이다. 한 번 정해진 인터페이스는 시간이 갈수록 사용하는 모듈이 많아지기 때문에 바꾸는데 엄청난 출혈을 각오해야 한다. 그 대표적인 예가 자바의 deprecated API라 한다.
인터페이스는 가능하면 변경하면 안 되며, 이를 달성하기 위해서는 여러 경우의 수에 대한 고려와 예측이 필요하다. 과도한 예측은 불필요한 작업을 만들기에, 설계자의 적절한 예측 능력이 필요하다.
커맨드의 역할
요청자와 처리자 사이의 계약을 커맨드라 지칭하고 있다. 여기서 처리자는 execute()란 인터페이스만 알면 어떠너 처리도 수행할 수 있다. 따라서 서로 의미적 관계가 없는 Command들도 execute()란 메소드로 무엇이든 확장할 수 있다. OCP 구조에서 서버가 확장할 수 있는 운신의 폭이 넓어진 반면 클라이언트는 서버가 어떤 처리를 하는지 무지해진다.
즉, 인터페이스 설계에서 적당한 추상화 레벨을 선택하는 것이 중요하다. 추상화라는 개념에 '구체적이지 않은' 정도의 의미로 약간 느슨한 개념을 갖고 있다.
그래디 부치가 말하는 추상화는 '추상화란 다른 모든 종류의 객체로부터 식별될 수 있는 객체의 본질적인 특징' 이라고 한다. 따라서 이 '행위'에 대한 본질적인 정의를 통해 인터페이스를 식별해야 한다.
포스팅에서 유일하게 이해되지 않는 부분은 '행위' 라는 부분이다. 혹여라도 지나가시던 객체 지향 고수분이 있으시다면 댓글을 큰 해소점이 될 것 같다.