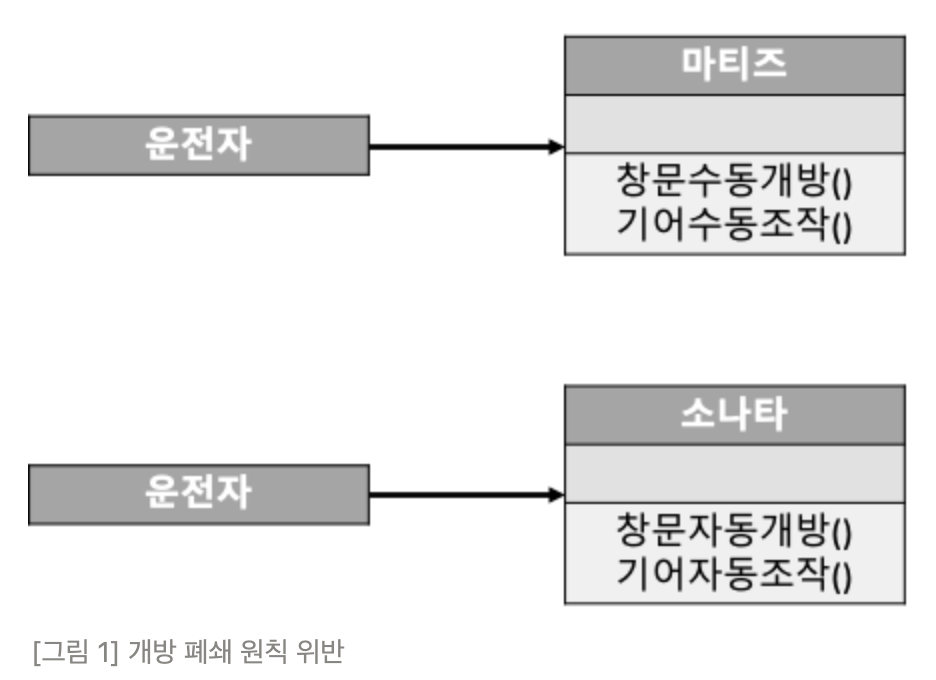
SOLID - ISP ( 인터페이스 분리 원칙 ) 에 대하여
OOP[객체지향 SW 설계의 원칙] ③ 인터페이스 분리의 원칙
[객체지향 SW 설계의 원칙] ③ 인터페이스 분리의 원칙
“사람은 다른 사람과 말을 할 때 듣는 사람의 경험에 맞추어 말해야만 한다. 예를 들어 목수와 이야기할 때는 목수가 사용하는 언어를 사용해야 한다.” - 플라톤의 파에톤(P...
zdnet.co.kr
좋은 내용이 있어 읽어보고 정리합니다. 단순한 개인 공부입니다. 잘못된 부분이 있으면 지적해주세요
인터페이스 분리 원칙?
ISP의 핵심은 '변화'가 핵심이 된다. 어떻게 변화할 것인지에 대해서 천천히 알아보자

다음과 같은 구조의 프로그램이 있다. 이 프로그램에서 제공하는 기능은 불법 결제 패턴에 해당하는 사용자 결제를 차단하고, 이를 담당자에게 메일로 리포팅하는 동작을 하게 된다.
하지만 여기서 추가적으로 SMS 리포팅 기능을 구현해야 하면 어떻게 될까?
아마도 CPRule에 메소드를 추가할 것인다. 그럼?
전혀 상관없는 클래스에게도 영향을 미치게 될 것이다. 이는 클래스의 재컴파일, 재배포 등과 같은 문제점을 야기한다.
이런 부분을 ISP를 통해서 해소할 수 있다. ISP 를 간단하게 정의하면 "클라이언트는 자기가 사용하지 않는 메소드에 의존 관계를 맺으면 안된다" 라는 것이다.
아직 한참 모자란 본인은 많은 부분에서 사용하지 않는 메소드가 있음에도 불구하고 의존 관계를 만들어서 사용했던 기억이 있다. 자 그럼 인터페이스를 사용해서 구조를 바꾸면 어떻게 될까?
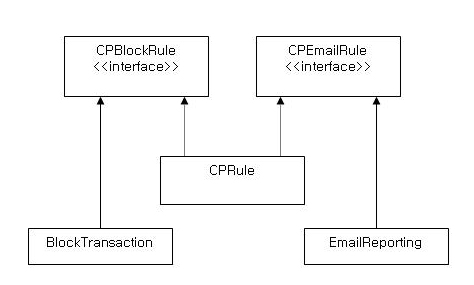
CPRule 이라는 클래스의 응집도는 높히대, 자신이 사용하지 않는 메소드를 분리해서 사용할 수 있게 된다.
이러한 부분은 BlockTransaction, EmailReporting 클래스가 직접 CPRule 에 접근하지 않아도 CPRule이 제공하는 서비스를 이용할 수 있게 된 것이다.
전형적인 ISP 를 보자

A, B, C 세 개의 클라이언트가 Service 인터페이스에 의존 관계를 맺고 있다.
만약에 Service 인터페이스의 어느 하나가 바귄다면, 세 클라이언트 모두를 재 컴파일, 재배포하는 아주 귀찮은 상황이 발생한다. 하지만 이를 ? 아래와 같이 변경한다면
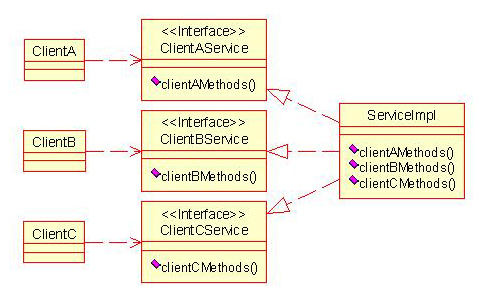
기존에 발생했던 변화의 확산이 일어나지 않는다.
로버트 C.마틴은 "클라이언트는 자신이 사용하지 않는 메서드에 의존 관계를 맺으면 안된다." 라고 했다.
이 뿐만 아니라 ISP를 이야기할 때 항상 인터페이스를 통한 메서드를 외부에 제공할 때는 최소한의 메서드만 제공하라는 것이다. 명심할 필요가 있다.
'OOP' 카테고리의 다른 글
| 객체 지향 그리고 SOLID (0) | 2020.12.03 |
|---|---|
| SOLID - LSP ( 리스코프 치환 원칙) 에 대하여 (0) | 2020.12.02 |
| SOLID - DIP ( 의존 관계 역전의 법칙 ) 에 대하여 (0) | 2020.12.01 |
| SOLID - SRP ( 단일 책임 원칙 ) 에 대하여 (0) | 2020.11.30 |
| SOLID - OCP ( 개방-폐쇄 원칙 ) 에 대하여 (0) | 2020.11.30 |